Phishing websites that evade threat detection

When CanIPhish launched, I hit a roadblock... My phishing websites and domains kept getting blocklisted by Google Safe Browsing, McAfee Safe Browser and so on. Incase you haven't seen what this looks like, it's essentially the mark of death for any domain and each time a domain got flagged, I was $12 out of pocket.
Obviously, I couldn't expect my customers to have successful phishing simulations when their targets would be greeted with this page. So I began venturing down the path of evading threat detection. Unfortunately, information on how to evade reputation blocklists like Google Safe Browsing are sparse and it's a closely guarded topic by these vendors for good reason. Ultimately, I had to stumble upon the answer through much trial and error.
Trial and error
Attempt #1 Initially, I thought Google was gathering DNS data on the sites I looked up (as I use 8.8.8.8 for DNS) and through DNS it was gathering data on what sites to index and scan. Likewise for McAfee, I used McAfee's Safe Search extension on my browser and I thought that's how my phishing websites were getting discovered. In response, I switched my DNS provider and turned off McAfee Safe Search.
This seemed to work to bypass McAfee Safe Search, but after 1-2 weeks I was again hit with the red wall of death... My phishing domains had yet again been blocklisted by Google.
Attempt #2 I then figured that Google must be stumbling across my domains through its indexing capability, I came to this conclusion due to the extended amount of time it took to blocklist my domains after the first failed attempt. I figured an easy way to get around this would be to implement some basic conditional routing. For example, if users went to phishingwebsite.com?v=t they would see something very different to what users would see if they just visited phishingwebsite.com.
Reference: The image on the left shows a request containing the simple querystring which routes to phishing material, the image on the right has no querystring and routes to training material.

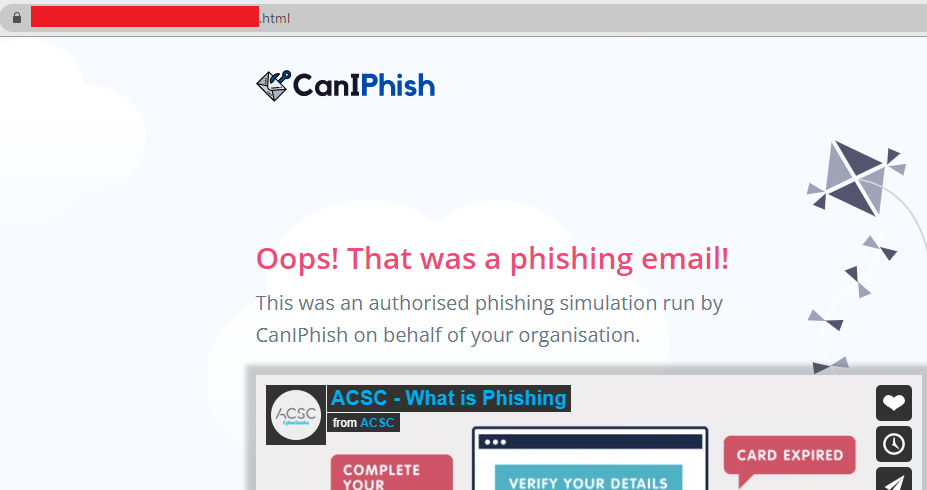
This actually stopped Google from indexing and scanning my phishing lookalike websites. All it ever saw was my innocous webpage, which included phishing awareness material. However... once phishing material began getting sent to Gmail users, I found that Google Safe Browsing had blocklisted all my phishing domains again.
I came to the conclusion that Google must be scanning Gmail users inboxes and detonating URLs including their querystring parameters after X time had passed. At this point, I had nearly a dozen domains blocklisted and it seemed like everytime I found a solution, there were additional detection techniques I hadn't considered.
After a day or two I figured I'd give evasion one final attempt... and I'd throw everything at it.
The Final Attempt (#3)
I ultimately gathered that conditional routing on all inbound web requests would need to be daisy-chained with the following additional capabilities to prevent Google and other OSINT providers from flagging my domains:
- Phishing links sent to targets must be single-use and become inoperable after the first detonation
- Querystring parameters will be used as the vehicle to perform conditional routing
- Querystring parameters must be encrypted or otherwise obfuscated to prevent analysis
- Querystring parameters must contain information relating to the target and phishing campaign
- Phishing links must expire 5 days after sending or when the phishing campaign becomes inactive – whichever is sooner. Primarily to avoid Google and OSINT providers from stumbling across and detonating an old unused link.
- Blocklist known Google and Security Vendor IPs
- Implement IP-based geo-restrictions based on information obtained during account creation and setup.
I found that capabilities 6 and 7 would be imperfect and technically difficult to implement and in the end, I decided not to implement them – they’re listed primarily for informational purposes.
The Solution
So now that my requirements were gathered, I needed to architect the solution. For added context, my entire SaaS platform is built on AWS so I decided to keep things in-house and craft the solution using entirely AWS native technologies.
The list of technologies along with a short overview of their purpose is as follows:
- Amazon S3: Hosting of the static HTML phishing websites and hosting of target user listings and their phishing status in a JSON flat file.
- Amazon Cloudfront: CDN that's caching the static phishing website hosted on S3. Also acting as the point of conditional routing through a 'Viewer request' function integration with Lambda@Edge.
- Amazon Route53: Hosting the DNS zone file and pointing all web requests (i.e. DNS 'A' queries) to the Cloudfront CDN.
- AWS Lambda@Edge: Performing querystring analysis to determine whether the requesting client is associated to an active campaign, the URL isn't older than 5 days and hasn't been used before.
- Amazon API Gateway: API endpoint that phishing websites contact once the site has been loaded and certain actions have been performed (e.g. entry of credentials)
- AWS Lambda: Function that the API Gateway points to. Updates the JSON flat file associated to the campaign target user listing to specify that a certain action has been recorded and to make the URL inoperable for future use.
- Amazon DynamoDB: NoSQL DB storing phishing campaign details, including when the campaign starts, ends and whether it's currently active.
Note: The above lsting isn't exhaustive and is only associated to phishing website hosting and evasion of threat intelligence providers. For hosting the full SaaS solution, a variety of additional technologies are used.
I've included the end-to-end solution architecture below.
Reference: Step 1. is the user making a request to obtain the phishing website and Step 2. is the user responding to an API via a JQuery event when the webpage has loaded and when certain actions are performed (e.g. entering credentials, clicking submit, etc.)

Wrapping up
There are likely far more efficient methods of achieving the same outcome, but this architecture has worked for me thus far. If you have any thoughts on how this could be improved, I'm all ears!
My aim with this article is to highlight how threat actors can utilise single-use and time-sensitive URLs to evade detection by the myriad of threat intelligence vendors including Google, McAfee and so on. Ultimately, the use of an in-flight sandbox or browser-based threat detection tooling is needed to provide true protection from phishing websites.
If you want to see these phishing websites in action, simply create a CanIPhish account and start phishing!
Sebastian Salla
A Security Professional who loves all things related to Cloud and Email Security.